
🥝 데이터베이스의 분할
서비스를 운영하면 할수록 데이터의 양이 점점 커지고 그 모든 데이터를 한 테이블에서 나아가 DB에서 감당하기 쉽지 않아진다. 즉, 데이터의 볼륨이 커지면 커질수록 DB의 read/write성능이 감소하고 DB의 병목 현상을 유발한다
그래서 DB를 분할하기 위해 사용할 방법인 파티셔닝과 샤딩을 알아보고자 한다
🥝 파티셔닝
파티셔닝은 매우 큰 테이블을 여러개의 테이블로 분할하는 작업이다. 큰 데이터를 여러 테이블로 나눠 저장하기 때문에 쿼리 성능이 개선된다. 이때, 데이터는 물리적으로 여러 테이블로 분산하여 저장되지만, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다는 점이 특징이다.
♬ 파티셔닝의 종류
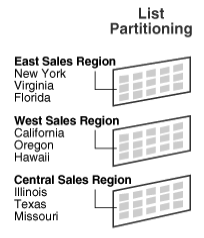
1. List Partitioning
지정된 값은 컬럼값을 기반으로 분류된다.
PARTITION BY LIST(원하는 컬럼) (
PARTITION EastSalesRagion VALUES IN (...) -- 원하는 컬럼
PARTITION WestSalesRagion VALUES IN (...)
PARTITION CentralSalesRagion VALUES IN (...)
)
장점
- 명확한 파티션 기준을 가지고 있고 특정 값에 대한 쿼리 성능이 향상된다
- 특정 값을 기준으로 한 집합이 된다
단점
- 값 목록이 변경되면 파티션을 재구성해야 하는 번거로움이 있다
- 일부 파티션에 데이터가 집중된다.
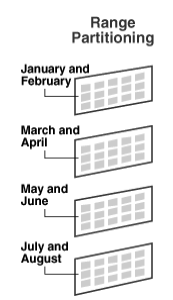
2. Range Partitioning
지정된 값을 범위별로 분리한다.
지정된 값은 연속적이고 겹치지 않아야 한다.
PARTITION BY RANGE(원하는 컬럼) (
PARTITION p0 VALUES IN (값1) -- MIN_VALUE ~ 값1
PARTITION p1 VALUES IN (값2)
PARTITION p2 VALUES IN (값3)
PARTITION p3 VALUES IN (값3)
);
-- 보통 마지막 줄에는 VALUES LESS THAN (MAX_VALUE)를 사용한다
장점
- 값의 범위에 따라 데이터가 분산되기 때문에 특정 값의 데이터 위치를 특정할 수 있다
- 날짜, 숫자 같은 범위에 따라 파티션을 관리한다
단점
- 불균형한 데이터 분포가 생긴다.
- 범위가 늘어나면 파티션을 늘려야한다.
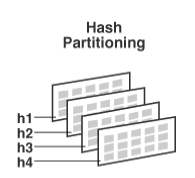
3. Hash Partitioning
해시 함수를 사용해서 데이터를 분할 할때 사용된다. 특정 컬럼의 값을 해싱하여 저장할 파티션을 선택한다. 하지만 여러 컬럼으로 해싱하는 것을 크게 권장하지 않는다.
PARTITION BY HASH(원하는 컬럼)
PARTITIONS 4;
-- 원하는 컬럼값에 해시 함수를 적용
-- 4개의 파티션으로 데이터를 분산시킨다장점
- 데이터가 균등하게 분산된다
- 추가적인 파티션 재구성을 할 필요없이 자동으로 균등하게 분산된다
단점
- 어떤 데이터가 어디 파티션에 있는지 특정하기 어렵다
- 패시 파티셔닝을 위한 컬럼을 변경하기가 어렵다
4. Composite Partitioning
위에서 말한 파티셔닝을 섞어서 사용할 수 있다. 분할된 파티션을 한번더 파티셔닝하게 되는것이다.
PARTITION BY RANGE( YEAR(날짜 컬럼) )
SUBPARTITION BY HASH( TO_DAYS(날짜 컬럼) ) -- 여기서 2개로 나뉜다.
SUBPARTITIONS 2 ( -- 여기서 3개로 나뉜다.
PARTITION p0 VALUES LESS THAN (1990),
PARTITION p1 VALUES LESS THAN (2000),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
-- 2개 x 3개 = 총 6개의 파티션
🥝 샤딩
샤딩은 동일한 스키마를 가지고 있는 여러대의 DB 서버들에 데이터를 작은 단위로 나누어 분산 저장하는 기법이다. 이때 이 단위를 샤드라고 부른다.
샤딩은 수평 파티셔닝의 일종이다. 차이점은 파티셔닝은 모든 데이터를 동일한 컴퓨터에 저장하지만 샤딩은 데이터를 서로 다른 컴퓨터에 분산한다는 것이다.
물리적으로 서로 다른 컴퓨터에 데이터를 저장하기 때문에 쿼리 성능 향상과 더불어 부하가 분산되는 효과까지 얻을 수 있다.즉, 샤딩은 데이터베이스 차원의 수평 확장인 셈인것이다.
하지만 물리적으로 데이터를 독립된 데이터베이스에 각각 분할하여 저장하기 때문에 여러 샤드에 걸친 데이터를 조인하는것이 굉장히 어렵다는 것이다. 또 한 DB에 집중적으로 데이터가 몰리면 성능이 느려지는 것은 여전하다. 때문에 데이터를 여러 샤드로 고르게 분배하는것이 중요하다.
♬ 샤딩의 종류
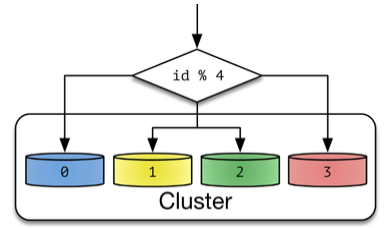
1. Hash Sharding
Hash 함수를 통해 반환되는 값으로 샤드를 결정하는 방법이다. 일반적으로 나머지값인 Modular를 사용한다. 샤드(분산 DB)수가 정해진 경우 사용하기가 좋다. DB 수가 변경되면 재정렬이 필요하다.
- 증설 작업에 큰 리소스가 소요하지 않는 이유로 Hash Sharding을 사용하면 좋다
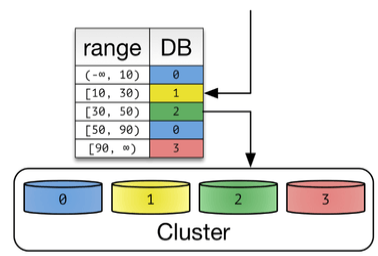
2. Range Sharding
컬럼값으로 샤드를 지정하는 방식이다. Hash Shard 대비 증설 작업에 리소스 소요가 적다. 따라서 데이터가 급격히 증가하는 경우 사용하면 좋다. 하지만, 특정 데이터베이스에 부하가 몰리는 경우가 생긴다
- 급격히 증가할 수 있는 성격의 데이터는 Range Sharding을 사용하는 것이 좋다
다만 이렇게 데이터를 분산 시켰는데 특정한 DB에만 부하가 몰릴 수 있다. 예를 들어 range shading을 접목하여 만든다면 최근 요청이 많아지면 한쪽의 DB만 트래픽을 받게 되는 것이다. 이렇게 트래픽을 몰리는 것을 방지하여 데이터가 몰리는 DB는 다시 재 샤딩을 하고, 트래픽이 저조한 DB는 다시 통합하는 작업이 필요하다.
🥝 reference
https://velog.io/@goseungwon/%ED%8C%8C%ED%8B%B0%EC%85%94%EB%8B%9D%EA%B3%BC-%EC%83%A4%EB%94%A9
https://hudi.blog/db-partitioning-and-sharding/
'CS > 💾 DB' 카테고리의 다른 글
| JOIN과 서브쿼리의 차이 (1) | 2024.07.21 |
|---|---|
| 💾 JOIN이란?? (0) | 2024.05.31 |
| 💾 동시성 문제를 해결하는 방법 (0) | 2024.04.27 |
| 💾 낙관적 락(Optimistic) 과 비관적 락(Pessimisitic) (1) | 2024.04.27 |
| 💾 MVCC, 트랜잭션 ( 5 ) (feat. MySQL과 PostgreSQL 비교) (1) | 2024.04.27 |