
🥽 굳이 Feign?
기존에 사용하던 방식은 Feign Client로 데이터를 전달하고 응답을 받아서 이어서 데이터를 처리하는 동기방식을 사용하고 있었다. 하지만 쿠폰서비스에서 유저서비스쪽에 쿠폰이 등록되는 것을 꼭 알아야 할까? 즉, 응답이 필요할 것인가 라는 것이다. 역시 답은 "아니다"라는 것이다. 쿠폰의 발급이 진행되었다면 사용자서비스에 해당 사용자의 상황만을 전달하고 사용자에게 쿠폰을 저장해주는 것은 유저서비스에서 진행하면 되는 것이다.
♬ 비동기 통신
그래서 비동기 통신을 해서 데이터를 처리하고자 한다.
기존에 Feign은 필요한 데이터를 응답받기위해 동기방식으로 처리된 것을 확인할 수있지만 굳이 응답을 받지 않고 데이터를 전달해서 해당 서비스에게 해야하는 일을 전달만 해주는 방식을 사용해서 비동기 방식으로 처리를 할 수 있다.
서비스간에 데이터를 주고 받는 방법 중 요청과 응답이 필요없기 때문에 Message Queue방식을 사용하는 방법이 있다.
대표적인 MQ를 사용하는 서비스는 RabbitMQ와 Kafka가 존재한다.
🥽 Kafka 도입, RabbitMQ??
♬ RabbitMQ가 아닌 Kafka를 선택한 이유
MQ방식을 사용하는 방식은 대표적으로 RabbitMQ 와 Kafka가 존재한다. 엄밀히 따지면 메세지 브로커를 사용하는 것과 이벤트 브로커를 사용하는 방식이기 때문에 엄연히 다르지만 데이터를 주고 받는 방식이 비슷하기에 비교해보고 왜 선택했는지 알아보자
우선 가장 중요한 포커스는 분산 서비스에 있었다. MSA방식에서 분산 서비스는 뗄래야 뗄수없는 중요한 과정이였다.
- 분산 서비스
- Kafka 는 하나의 topic을 여러개의 파티션으로 나누어 분산 처리를 보다 유연하게 도와줄 수 있다.
- RabbitMQ는 하나의 topic(queue)을 여러개로 나눌수 없다. 때문에 추가적으로 서비스가 생긴다면 따로 처리해주어야한다.
- 데이터의 휘발성
- Kafka는 topic을 구성하고 그곳에 메세지를 저장한다. 물론 subscriber(consumer)가 데이터를 가져간다고 하더라도 데이터가 지워지지 않고 저장된다. 그리고 offset(메세지 번호)를 저장하고 후에 해당 파티션을 담당하고 있는 서버가 사용이 불가능한 상태가 되어도 offset을 기억하고 있는 groupId가 다른서버나 회복된 서버에게 다시 알려주어 사용할 수 있다
- RabbitMQ 는 메세지를 받게되면 ACK을 보내고 해당 메세지를 삭제한다
- 용도의 차이
- Kafka 는 클러스터와 topic의 partition을 통한 병렬처리가 가장 큰 차별점인 만큼 방대한양의 데이터를 처리한다는 것이 장점이 된다
- RabbitMQ는 데이터를 처리하는 것보다 관리를 하거나 다양한 기능을 구현하기 위한 서비스를 구축할때(e.g PDF처리, 이미지 관련 처리등 시간이 오래 걸리는 작업) 장점이 더욱 부각된다.
즉, 쿠폰을 저장하는 insert 작업은 복잡한 라우팅도 아니고 최대 처리량이 중요한 작업이고 혹여 메세지가 손실되었을 경우 다시 작업을 진행하기 위해 메세지를 반영구적으로 저장하는 Kafka가 어울릴 수 있다는 것이다.
🥽 구현
우선 Kafka의 서버를 3개로 나누어야 한다.
로컬의 환경에서 진행하기 때문에 서버를 늘려주기 위해 server.properties 를 2개더 추가 시키고 진행을 한다. 그리고 각각 서버를 9092, 9093, 9094 로 연결해서 진행했다.
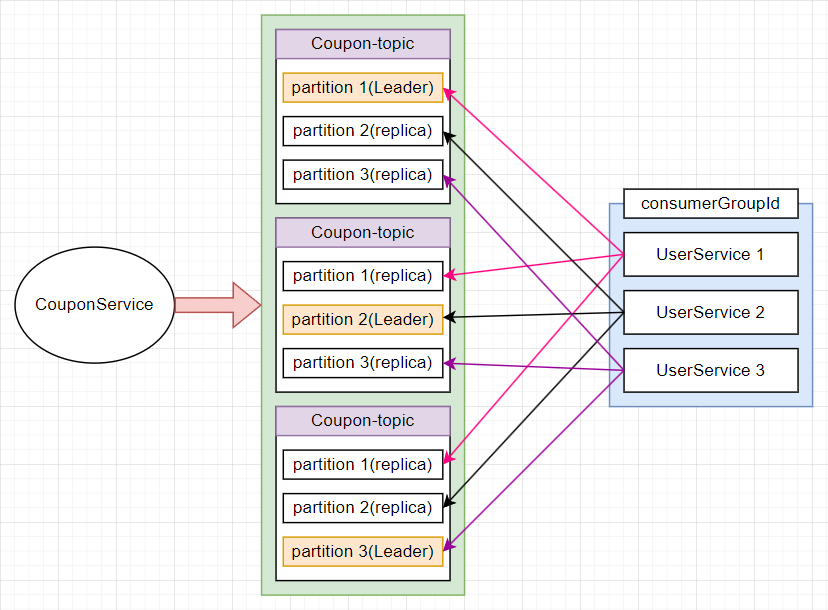
사용될 토픽인 coupon-topic도 3개의 토픽에 3개의 partition을 레플리카 방식으로 만들어두어야 한다

이런식으로 설정을 먼저 해준다면 각 토픽에 leader와 replicate된 partition이 설정된것을 확인 할 수 있다.
♬ Producer 서비스 쪽 코드

- 전달하고자 하는 브로커(서버) 3개를 모두 등록해주어야 한다. 클러스터 내의 브로커를 지정해서 등록된 서버를 모두 등록해준다.
- send에서 지정된 coupon-topic으로 데이터를 전달한다.
♬ Consumer 서비스 쪽 코드
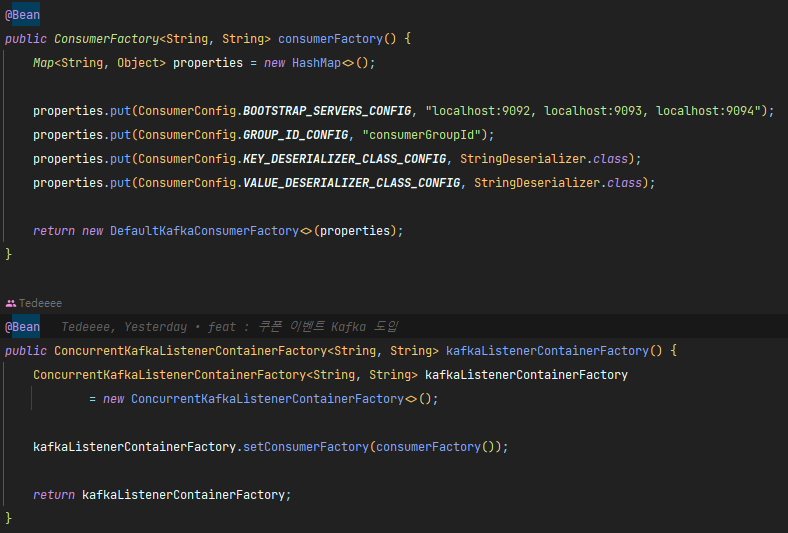
- 받는 쪽의 설정에서도 카프카 브로커(서버)의 설정을 그대로 진행한다.
- 이제 3개의 서비스를 추가로 생성하면 되는데 이때 터미널을 통해 서버를 생성하면 된다 그러면 자동으로 각각의 토픽과 각 파티션을 연결하는 것을 확인할 수 있다.

- 각각의 서버마다 연결된 것을 확인 할 수 있다. 이렇게 각 서버가 partition이 연결되면 어떤 결과가 나올까
🥽 테스트
3개의 서버를 다루기 전에 비교를 해보고자 한다. 분산된 서비스에서 더욱 유연하고 빠른 처리량을 보인다고 했다. 과연 이는 사실일까?
♨ 공통 준비
우선 1만개의 데이터로 비교해보고자 한다. 물론 카프카는 초당 만개정도는 우습게 처리할 수 있기 때문에 만개의 데이터는 크게 성능 테스트에 사용할 수 없겠지만 1만개로 시도해보고자 한다.
- 쿠폰이 특정 시간에 등록이 되고 그 시간이 되자마자 1만명의 사람들이 쿠폰 발급을 클릭한다 쿠폰이 해당 유저의 쿠폰함에 처리되기 까지의 시간을 알아보자

이런식으로 event와 사용자가 등록되어 진행된다 이제 서버 갯수별 처리 테스트를 해보자
♨ 1개의 서버
우선 서버를 한개로 만들려면 partition도 한개로 만들어야 한다 분산 서비스가 아닌 상태이기 때문에 정확한 측정을 위해 하나만 만들어서 진행한다.

그리고 정확히 56분에 시작하는 쿠폰 증정 이벤트가 시작된다

종료 시간

잘 안보일 수 있지만 1분 52초 걸리는 것을 확인할 수 있다. 여러번의 테스트 후 평균 2분 정도의 소요시간이 걸리는 것을 확인 할 수 있다.

DB의 재고도 정확히 줄어드는 것을 확인 할 수 있다.
♨ 3개의 서버
다시 원래대로 진행을 해주어야 한다. 해당 topic의 파티션을 3개로 다시 설정해서 진행해보자

비슷하게 잘 안보이지만 1분 54초로 거의 비슷한 처리 결과를 알 수 있다. 처음엔 이해 할 수 없었다. 대용량 트래픽 처리량이 굉장히 빠르기 때문에 도입한 Kafka는 3개의 서버로 증설했고 파티션까지 나눴음에도 불구하고 기대한 효과를 전달할 수 없었다. 왜일까 그 대답은 각 서버의 처리 시간을 보고 알 수 있었다.
각 서버의 처리 시간
- 1번 서버

- 2번 서버

- 3번 서버

3개의 서버를 보면 공통적으로 발견되는 규칙이 존재한다. 바로 2~3초 정도 쉰다는 것이다. 이것이 무엇을 의미하냐면 해당 서버의 최대 용량을 사용하고 있지 않다는 것이다. 데이터를 partition에 전달하는 서버는 1개이다. 라운드 로빈 방식으로 일정 갯수의 데이터를 한번에 보내게 되는데 그렇게 전달받은 각 3개의 서버는 그 일을 처리하고 다음 메세지가 오기 전까지 3초 정도는 쉴 수 있을정도로 처리량이 빠른 것이다.
♬ 결론
1개의 프로듀서 1개의 컨슈머
- 1개가 1만개를 전달하면 1개의 컨슈머는 열심히 처리하여 2분 동안 1만개의 데이터를 처리한다
1개의 프로듀서 3개의 컨슈머
- 1개가 1만개를 전달하면 3개의 컨슈머는 느긋하게 처리하며 2분을 보낸다
공통적으로 2분이 걸리는 이유는 프로듀서에서 1만개의 데이터를 파티션에 보내는데 걸리는 시간이기 때문이다. 즉, 1개의 컨슈머가 1만개의 데이터를 처리하는 속도가 3개의 1만개 데이터를 처리하는 속도와 같다는 뜻이다. 그만큼 빠르다
- 더 빠른 속도로 데이터를 전달
- 더욱 많은 데이터를 전달
- 로직의 복잡도
만약 위의 3가지가 높아지면 높아질수록 더욱 확연한 성능의 차이를 보여줄 것이다.
🥽 느낀점
동기방식과 비교해서 훨씬 더 빠른 성능을 기대할 수 있는 비동기 방식을 사용해보았다 물론 데이터는 훨씬 빠르게 처리했지만 응답이 필요한 상황이라면 동기 방식을 사용하는 것이 훨씬 안정적이다. 대표적인 예를 들면 재고를 관리하는 상황에서 재고에 문제가 발생하면 주문이 나가지 말아야한다. 하지만 비동기 방식으로 통신을 하게 되면 주문쪽에선 재고의 잔여갯수에 관심이 없다는 뜻으로 간주되어 그대로 진행한다. 이는 추후에 큰 문제로 이어지게 되기 때문에 이와 같은 방식에서는 선택을 잘해서 진행을 해야한다.
한개의 파티션과 한개의 서버로 kafka의 데이터를 처리하는 것과 다수의 파티션과 다수의 서버의 비교는 생각보다 굉장히 큰 데이터가 필요하다 라는 생각을 하게 되었다. 또한 그만큼 카프카는 정말 대용량의 데이터를 순식간에 처리할 수 있다는 사실을 알았다.
Kafka를 구성할때는 서버의 문제로 인해 데이터의 유실을 방지하기 위해 3개의 서버를 두는 것이 암묵적인 룰처럼 다루고 있기 때문에 3개로 구성하는 것도 진행해보았다. 기존에 가볍게 배울때는 구성과 진행 방식만을 알아보았는데 이번 기회에 실제로 데이터를 다뤄보고 leader와 replicate를 직접 다뤄볼 수 있어서 굉장히 좋았다. 직접 구현하게 되면서 더욱 공부를 하게 된것 같아 좋았다.
근데 RabbitMQ는 사용할 일이 없을까? 아니다. RabbitMQ는 ACK을 주고 받으며 데이터의 전달의 상황을 정확히 확인하기 때문에 시간이 오래 걸리는 작업이나 안정적으로 백그라운드에서 작업이 필요할 경우, 애플리케이션 간 내부 통신 및 통합이 필요할 떄 적합하다. 이렇게 부하가 높은 작업이 발생하면 부하를 한개의 서비스에서 감당하는 것이 아닌 다른 서비스로 전달하여 부하를 나누는 방법으로 사용 할 수 있다.
RabbitMQ와 Kafka를 비교하다보면 마치 두개 중 하나를 사용하는 것처럼 생각할 수 있지만 그것은 아니다 두개는 똑같은데 다른 라이브러리가 아닌 사용처 부터가 다르다. 때문에 앞으로 서비스가 거대해지거나 복잡한 라우팅이 필요한 경우 RabbitMQ를 추가적으로 제작하여 사용할 수 있다는 것이 중요하다고 생각했다.
🥽 참고
'프로젝트 > 항해99 개인 프로젝트' 카테고리의 다른 글
| 🚢 상품의 캐싱처리 (feat. 캐싱하기) (0) | 2024.06.01 |
|---|---|
| 🚢 Redis를 사용해서 선착순으로 쿠폰 발급하기 (0) | 2024.05.13 |
| 🚢 중간테이블로 인한 JPA의 N+1문제 (0) | 2024.05.09 |
| 🚢 MSA의 동시성 제어를 위한 Lock 사용(feat. Redis의 분산락) (1) | 2024.04.30 |
| 🚢 Feign Client 와 RestTemplate (0) | 2024.04.30 |