
💧 시작에 앞서
현재 나의 서비스는 주문을 하기 위해 OrderService에서 feign client를 이용해서 ProductService를 통해 차감되어어야 하는 데이터가 있고 그에대한 반환값을 전달해야 하는데 이때 만약 Product 쪽에 문제가 발생한다면 Transactional의 특성으로 인해 전부다 rollback이 될테고 예외가 발생하게 될 것이다.
하지만 이건 문제가 있다. 왜냐하면 문제는 ProductService에 존재하는데 정작 사용자에게 나타나는 오류 메세지는 마치 OrderService의 서버가 문제가 있는것처럼 나타나기 때문이다. 이건 너무 MSA 방식과 거리가 멀 다는 것을 알 수 있다.
각각의 서비스의 결합도는 낮아야 하는데 한개의 서비스가 오류가 발생하면 다른 곳에 영향을 받기 때문이다. 그래서 이를 해결하고자 CircuitBreaker 와 Retry를 사용해 서비스의 장애를 지속시키지 않고 빠르고 안정적으로 서비스를 다시 제공하려고 한다.
Resilience4J
Retry와 CircuitBreaker 를 간단하게 알아보기 전에 Resilience4J에 대해서 알아보자면 함수형 프로그래밍으로 설계된 경량, 장애 허용 라이브러리로 Resilience를 적용하면 외부 서비스에 장애가 발생하여도 자신의 시스템은 계속 작동할 수 있는것이다.
원래 Hystrix도 있는데 이것은 deprecated 되었기 때문에 Resilience4J를 사용하고자 한다.
Retry
하나의 요청에 대해 요청이 실패했을 경우 해당 요청을 다시 시도한다. 계속 실패할 경우 다른 응답을 반환한다.
지정된 횟수만큼 요청을 재시도하고 일정 시간 간격 또는 BackOff전략으로 재시도 간격도 조절할 수 있다
사용하는 상황
- 일시적인 오류나 지연에 대응해서 재시도를 통해 성공할 가능성을 높이고자하는 상황에서 적합
- 네트워크 문제, DB 문제, 일시적인 서비스 다운 등의 장애에 대응하기 위해 사용
- 너무 잦은 재시도는 장애가 반복적으로 발생하게 되면서 서비스의 신뢰도가 내려간다
CircuitBreaker
요청들을 지켜보다가 지속적으로 실패하는 경우, 잠시 요청을 차단해서 장애를 전파되지 않도록 한다
장애가 지속되면 해당 서비스에 대한 요청을 차단한다. 그로 인해 전체 서비스의 과부하를 방지한다
CircuitBreaker는 크게 3가지의 상태를 기반으로 동작한다
- close : 장애가 발생하지 않은 정상 상태
- open : 장애가 발생한 상태
- half-open : fallback 응답을 수행하고 실패율을 측정해서 close 또는 open으로 변경될 수 있는 상태
CircuitBreaker 는 원자성이 보장되고 특정 시점에 하나의 쓰레드만이 서킷브레이커의 상태나 슬라이딩 윈도우를 업데이트 할 수 있는 것이다. 하지만 함수 호출은 동기화하지 않기 떄문에 성능적 약점과 병목을 발생시킬수 있다.
슬라이딩의 윈도우가 10개라고 15개의 쓰레드 요청을 막는것이 아니라 전부다 처리한다.
※ 동시에 처리할 수 있는 설정은 BulkHead 에서 지원한다.
관련 설정
| 구분 | 설정 | 기본값 | 설명 |
| Sliding Window | slidingWindowType | COUNT_BASED | 요청 결과를 기록할 sliding window 타입 - COUNT_BASED - TIME_BASED |
| slidingWindowSize | 100 | sliding window 크기 | |
| minimumNumberOfCalls | 100 | failureRate, slowCallRate를 계산하기 위한 최소 갯수 | |
| recordExceptions | empty | 실패로 집계할 예외 | |
| ignoreExceptions | empty | 실패로 집계되지 않을 예외 | |
| recordFailurePredicate | throwable → true | 실패로 집계할 예외인지 판단할 Predicate | |
| ignoreExceptionPredicate | throwable → false | 실패로 집계하지 않을 예외인지 판단할 Predicate | |
| close → open | failureRateThreshold | 50 | 임계치로써 넘어가면 open으로 변경 |
| slowCallRateThreshold | 100 | 임계치로써 넘어가면 open으로 변경 | |
| slowCallDuraionThreshold | 60000ms | 해당 설정값 이상이라면 slow call로 판단 | |
| open → half open | waitDurationInOpenState | 60000ms | open 상태에서 half open 으로 변경 대기 시간 |
| automaticTransitionFrom OpenToHalfOpenEnabled |
false | 자동 전환 여부 - true : 위의 설정값 시간동안 대기하지 않고 전환 - false : 위의 설정값 체크를 위한 별도 스레드 생성 |
|
| half open | permittedNumberOfCalls InhalfOpenState |
10 | half open 상태일 때 허용할 call 의 갯수 |
| half open → open | maxWaitDuration InHalfOpenState |
0 | half open 상태에서 open 상태로 변경되기전 최대 유지 시간 0인 경우 일부 허용된 Call이 완료될 때까지 대기 |
💧 Resilience4J를 사용한 CircuitBreaker 적용
라이브러리 설정

properties 설정

- 간단하게 기본적인 것을 설정해보았다.
- 10개씩 체크 할 것이고 50%로 임계치를 설정했기에 10개중 5개가 실패하면 open 상태로 변경되고 10초후에 half-open으로 변한다
Service 설정
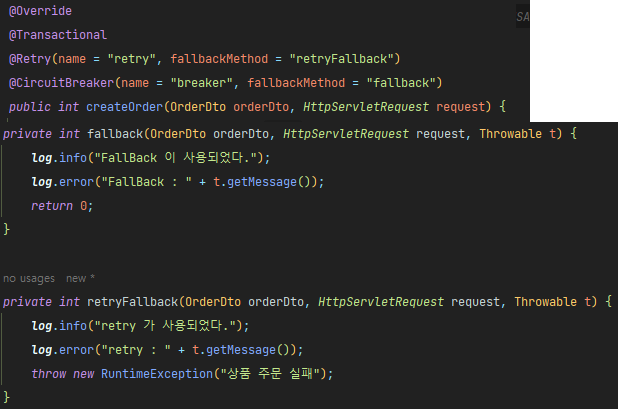
- 여기서 중요한건 @CircuitBreaker 어노테이션과 가장 밑의 fallback과 recover 메소드이다.
- 동작 순서
- createOrder 라는 메소드가 시작된다
- Feign Client 에서 사용하는 decreaseCount에서 ProductService에게 요청한다
- Product이 응답을 할 수 없다면 응답에 문제가 발생한다
- 혹여 서비스가 죽은 것이 아닐 수 있기 때문에 retryable이 3번의 요청을 더한다
- 여기서 요청을 하는 과정에서 retry가 3번 일어나게 되면서 3번의 요청을 count한다
- 실패 할 때마다 fallback이 실행되고 클라이언트에게 무엇을 전달할지 정한다.
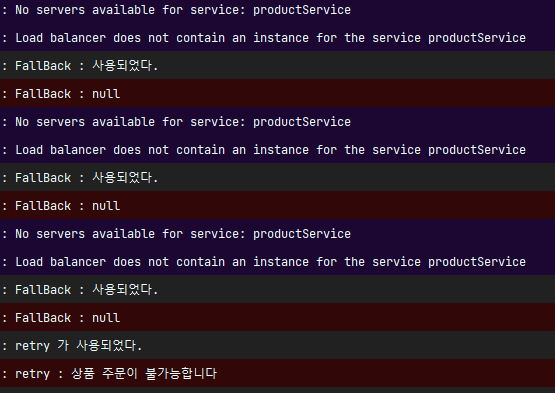
- fallback에서 전달한 요청을 retryfallback 메소드가 최종적으로 받아들여 "상품 주문이 불가능합니다" 예외처리를 받아 똑같이 전달하는 것을 볼 수 있다
💧 CircuitBreaker Test
우선 retry은 좀 더 미루고 Circuit만 사용해서 test를 진행해보고자 한다
- 10번의 요청중 40%의 실패율을 같기 위해 6번의 성공 4번의 실패를 하려고 한다
- 그러면 circuit 이 open으로 변경된다. 그리고 해당 open 상태는 10초 동안 유지된다

- failureRate 는 10개의 size에서 몇%의 실패율을 가지고 있는지 보여준다.
- 40% 이상이기에 open으로 변경되고 10초가 지나기 전까진 notPermittedCalls의 횟수만 올라간다. 왜냐하면 open상태에서의 요청은 서비스가 열려있던 닫혀있던 우선 반환을 문제가 있다고 보기 때문이다.

- 이제 10초가 지나면 다시 size에 맞춰 계산을 하기 시작한다. 이후의 요청은 모두 성공을 해보았다

- 모두 다 성공을 했더니 -1% 라는 값으로 리셋되고 state가 close 상태로 변경되었다는 것을 알 수 있다.
- 하지만 half-open 상태에서 또다시 40% 이상의 실패율을 기록하면 다시 close 된다.
slowCall 과 관련된 내용은 응답 속도에 관련되어 있다
위에 표를 보면 slowCallRate 는 똑같이 %를 뜻하고 slowCall이 10번 중 10번다 느리다면 open으로 변경된다
또한 응답속도가 느리다고 판단하는 것은 Duration에 값을 설정하게 된다. 기본값은 1분이다.
즉, 현재 설정 값은 10번의 요청 중 10번의 응답이 1분 이상 걸린다면 응답의 유무와 상관없이 open 형태로 변하는 것이다
💧 Retry Test와 circuit을 합쳐보자
Retry는 위에서 말한것 처럼 서비스가 문제가 일시적인 것으로 인해 오류가 발생했을것을 대비하여 일정한 횟수만큼 요청을 하는 것이다.
이것을 테스트하는 집중적인것은 바로 open과 close보다는 3번의 재요청중 성공하는 요청이 존재한다면 정상적으로 응답을 한다는 것이다.
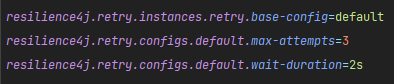
- @retry의 설정을 보자면 maxAttempts는 다시 요청하는 횟수, wait은 한 번 재요청하고 2초뒤 다시 요청하는 것이다. 즉, 코드의 해석은 재요청을 2초 간격으로 3번하는 것이다.

- 근데 retry가 3번의 요청을 하는데 그것을 전부다 circuitbreaker가 1개씩으로 처리하기 때문에 한번의 요청에 3개가 올라가는 것이다.
- 하지만 클라이언트는 3번 요청한게 아니라 1번 요청했기 때문에 1번으로 처야한다. 기본적으로 retry는 circuitBreaker보다 우선순위가 뒤에 있기 때문에 그것을 바꿔 주어야 한다

- 숫자가 높을 수록 우선 순위가 높다. 이제 다시 실행해보면 retry가 3번 먼저 발생하고 그것이 10번이 쌓이면 open 된다

- 로그가 길어서 잘라서 가져왔다. retry가 3번 반복되고 fallback이 발생한다. 그리고open이 된 순간부터 retry로 가지 않고 바로 fallback으로 간다는 것을 확인 할 수 있다.
- 만약 retry중 서버가 정상적인 반영이 되면 정상적으로 실행된다는 것을 알 수 있다.

💧 TimeLimiter
Resilience4J의 구성 요소 중 TimeLimiter라는 것이 존재한다. 이것은 전체적인 작업 처리에 대한 제한 시간을 두는 것이다. 이를 설정할때는 주의 사항이 있다
예를 들어 생각해보자
- 어떠한 요청은 5초의 응답시간이 걸린다
- 해당 TimeLimiter를 3초로 설정했다
- 때문에 전체적인 작업 처리가 3초를 지났기에 fallback 처리가 된다
- 해당 요청의 전체적인 작업 처리 자체가 3초이기에 retry조차도 실행되지 못한다.
- 더 나아가 TimeLimiter를 10초로 설정했다고 하더라도 retry까지 모두 계산하면 시간을 넘기때문에 retry를 진행하다 멈춰버린다
timeout의 값은 신중히 설정되어야 한다 그래서 기본적으로 TimeLimiter의 timeout 값은 CircuitBreaker와 slowCallDurationThreshold와 OpenFeign의 connectionTimeout, readTimeout 보다 크게 설정되어야한다. 그래야 응답이 조금 오래 걸리는 상황에서도 정상적으로 처리가 가능하다. 그 외에 slowCall에 대하여 재시도를 고려까지 한다면 더욱 신중히 값을 정해주어야 한다.
'프로젝트 > 항해99 개인 프로젝트' 카테고리의 다른 글
| 🚢 MSA의 동시성 제어를 위한 Lock 사용(feat. Redis의 분산락) (1) | 2024.04.30 |
|---|---|
| 🚢 Feign Client 와 RestTemplate (0) | 2024.04.30 |
| 🚢 재고 관리를 위한 동시성 제어 (Monolithic Architecture) (2) | 2024.04.27 |
| 🚢 WishList가 장바구니? (Redis 의 Hash타입 사용) (0) | 2024.04.26 |
| 🚢 이메일 인증 코드, Session 에서 Redis로 (0) | 2024.04.26 |
💧 시작에 앞서
현재 나의 서비스는 주문을 하기 위해 OrderService에서 feign client를 이용해서 ProductService를 통해 차감되어어야 하는 데이터가 있고 그에대한 반환값을 전달해야 하는데 이때 만약 Product 쪽에 문제가 발생한다면 Transactional의 특성으로 인해 전부다 rollback이 될테고 예외가 발생하게 될 것이다.
하지만 이건 문제가 있다. 왜냐하면 문제는 ProductService에 존재하는데 정작 사용자에게 나타나는 오류 메세지는 마치 OrderService의 서버가 문제가 있는것처럼 나타나기 때문이다. 이건 너무 MSA 방식과 거리가 멀 다는 것을 알 수 있다.
각각의 서비스의 결합도는 낮아야 하는데 한개의 서비스가 오류가 발생하면 다른 곳에 영향을 받기 때문이다. 그래서 이를 해결하고자 CircuitBreaker 와 Retry를 사용해 서비스의 장애를 지속시키지 않고 빠르고 안정적으로 서비스를 다시 제공하려고 한다.
Resilience4J
Retry와 CircuitBreaker 를 간단하게 알아보기 전에 Resilience4J에 대해서 알아보자면 함수형 프로그래밍으로 설계된 경량, 장애 허용 라이브러리로 Resilience를 적용하면 외부 서비스에 장애가 발생하여도 자신의 시스템은 계속 작동할 수 있는것이다.
원래 Hystrix도 있는데 이것은 deprecated 되었기 때문에 Resilience4J를 사용하고자 한다.
Retry
하나의 요청에 대해 요청이 실패했을 경우 해당 요청을 다시 시도한다. 계속 실패할 경우 다른 응답을 반환한다.
지정된 횟수만큼 요청을 재시도하고 일정 시간 간격 또는 BackOff전략으로 재시도 간격도 조절할 수 있다
사용하는 상황
- 일시적인 오류나 지연에 대응해서 재시도를 통해 성공할 가능성을 높이고자하는 상황에서 적합
- 네트워크 문제, DB 문제, 일시적인 서비스 다운 등의 장애에 대응하기 위해 사용
- 너무 잦은 재시도는 장애가 반복적으로 발생하게 되면서 서비스의 신뢰도가 내려간다
CircuitBreaker
요청들을 지켜보다가 지속적으로 실패하는 경우, 잠시 요청을 차단해서 장애를 전파되지 않도록 한다
장애가 지속되면 해당 서비스에 대한 요청을 차단한다. 그로 인해 전체 서비스의 과부하를 방지한다
CircuitBreaker는 크게 3가지의 상태를 기반으로 동작한다
- close : 장애가 발생하지 않은 정상 상태
- open : 장애가 발생한 상태
- half-open : fallback 응답을 수행하고 실패율을 측정해서 close 또는 open으로 변경될 수 있는 상태
CircuitBreaker 는 원자성이 보장되고 특정 시점에 하나의 쓰레드만이 서킷브레이커의 상태나 슬라이딩 윈도우를 업데이트 할 수 있는 것이다. 하지만 함수 호출은 동기화하지 않기 떄문에 성능적 약점과 병목을 발생시킬수 있다.
슬라이딩의 윈도우가 10개라고 15개의 쓰레드 요청을 막는것이 아니라 전부다 처리한다.
※ 동시에 처리할 수 있는 설정은 BulkHead 에서 지원한다.
관련 설정
| 구분 | 설정 | 기본값 | 설명 |
| Sliding Window | slidingWindowType | COUNT_BASED | 요청 결과를 기록할 sliding window 타입 - COUNT_BASED - TIME_BASED |
| slidingWindowSize | 100 | sliding window 크기 | |
| minimumNumberOfCalls | 100 | failureRate, slowCallRate를 계산하기 위한 최소 갯수 | |
| recordExceptions | empty | 실패로 집계할 예외 | |
| ignoreExceptions | empty | 실패로 집계되지 않을 예외 | |
| recordFailurePredicate | throwable → true | 실패로 집계할 예외인지 판단할 Predicate | |
| ignoreExceptionPredicate | throwable → false | 실패로 집계하지 않을 예외인지 판단할 Predicate | |
| close → open | failureRateThreshold | 50 | 임계치로써 넘어가면 open으로 변경 |
| slowCallRateThreshold | 100 | 임계치로써 넘어가면 open으로 변경 | |
| slowCallDuraionThreshold | 60000ms | 해당 설정값 이상이라면 slow call로 판단 | |
| open → half open | waitDurationInOpenState | 60000ms | open 상태에서 half open 으로 변경 대기 시간 |
| automaticTransitionFrom OpenToHalfOpenEnabled |
false | 자동 전환 여부 - true : 위의 설정값 시간동안 대기하지 않고 전환 - false : 위의 설정값 체크를 위한 별도 스레드 생성 |
|
| half open | permittedNumberOfCalls InhalfOpenState |
10 | half open 상태일 때 허용할 call 의 갯수 |
| half open → open | maxWaitDuration InHalfOpenState |
0 | half open 상태에서 open 상태로 변경되기전 최대 유지 시간 0인 경우 일부 허용된 Call이 완료될 때까지 대기 |
💧 Resilience4J를 사용한 CircuitBreaker 적용
라이브러리 설정
properties 설정
- 간단하게 기본적인 것을 설정해보았다.
- 10개씩 체크 할 것이고 50%로 임계치를 설정했기에 10개중 5개가 실패하면 open 상태로 변경되고 10초후에 half-open으로 변한다
Service 설정
- 여기서 중요한건 @CircuitBreaker 어노테이션과 가장 밑의 fallback과 recover 메소드이다.
- 동작 순서
- createOrder 라는 메소드가 시작된다
- Feign Client 에서 사용하는 decreaseCount에서 ProductService에게 요청한다
- Product이 응답을 할 수 없다면 응답에 문제가 발생한다
- 혹여 서비스가 죽은 것이 아닐 수 있기 때문에 retryable이 3번의 요청을 더한다
- 여기서 요청을 하는 과정에서 retry가 3번 일어나게 되면서 3번의 요청을 count한다
- 실패 할 때마다 fallback이 실행되고 클라이언트에게 무엇을 전달할지 정한다.
- fallback에서 전달한 요청을 retryfallback 메소드가 최종적으로 받아들여 "상품 주문이 불가능합니다" 예외처리를 받아 똑같이 전달하는 것을 볼 수 있다
💧 CircuitBreaker Test
우선 retry은 좀 더 미루고 Circuit만 사용해서 test를 진행해보고자 한다
- 10번의 요청중 40%의 실패율을 같기 위해 6번의 성공 4번의 실패를 하려고 한다
- 그러면 circuit 이 open으로 변경된다. 그리고 해당 open 상태는 10초 동안 유지된다
- failureRate 는 10개의 size에서 몇%의 실패율을 가지고 있는지 보여준다.
- 40% 이상이기에 open으로 변경되고 10초가 지나기 전까진 notPermittedCalls의 횟수만 올라간다. 왜냐하면 open상태에서의 요청은 서비스가 열려있던 닫혀있던 우선 반환을 문제가 있다고 보기 때문이다.
- 이제 10초가 지나면 다시 size에 맞춰 계산을 하기 시작한다. 이후의 요청은 모두 성공을 해보았다
- 모두 다 성공을 했더니 -1% 라는 값으로 리셋되고 state가 close 상태로 변경되었다는 것을 알 수 있다.
- 하지만 half-open 상태에서 또다시 40% 이상의 실패율을 기록하면 다시 close 된다.
slowCall 과 관련된 내용은 응답 속도에 관련되어 있다
위에 표를 보면 slowCallRate 는 똑같이 %를 뜻하고 slowCall이 10번 중 10번다 느리다면 open으로 변경된다
또한 응답속도가 느리다고 판단하는 것은 Duration에 값을 설정하게 된다. 기본값은 1분이다.
즉, 현재 설정 값은 10번의 요청 중 10번의 응답이 1분 이상 걸린다면 응답의 유무와 상관없이 open 형태로 변하는 것이다
💧 Retry Test와 circuit을 합쳐보자
Retry는 위에서 말한것 처럼 서비스가 문제가 일시적인 것으로 인해 오류가 발생했을것을 대비하여 일정한 횟수만큼 요청을 하는 것이다.
이것을 테스트하는 집중적인것은 바로 open과 close보다는 3번의 재요청중 성공하는 요청이 존재한다면 정상적으로 응답을 한다는 것이다.
- @retry의 설정을 보자면 maxAttempts는 다시 요청하는 횟수, wait은 한 번 재요청하고 2초뒤 다시 요청하는 것이다. 즉, 코드의 해석은 재요청을 2초 간격으로 3번하는 것이다.
- 근데 retry가 3번의 요청을 하는데 그것을 전부다 circuitbreaker가 1개씩으로 처리하기 때문에 한번의 요청에 3개가 올라가는 것이다.
- 하지만 클라이언트는 3번 요청한게 아니라 1번 요청했기 때문에 1번으로 처야한다. 기본적으로 retry는 circuitBreaker보다 우선순위가 뒤에 있기 때문에 그것을 바꿔 주어야 한다
- 숫자가 높을 수록 우선 순위가 높다. 이제 다시 실행해보면 retry가 3번 먼저 발생하고 그것이 10번이 쌓이면 open 된다
- 로그가 길어서 잘라서 가져왔다. retry가 3번 반복되고 fallback이 발생한다. 그리고open이 된 순간부터 retry로 가지 않고 바로 fallback으로 간다는 것을 확인 할 수 있다.
- 만약 retry중 서버가 정상적인 반영이 되면 정상적으로 실행된다는 것을 알 수 있다.
💧 TimeLimiter
Resilience4J의 구성 요소 중 TimeLimiter라는 것이 존재한다. 이것은 전체적인 작업 처리에 대한 제한 시간을 두는 것이다. 이를 설정할때는 주의 사항이 있다
예를 들어 생각해보자
- 어떠한 요청은 5초의 응답시간이 걸린다
- 해당 TimeLimiter를 3초로 설정했다
- 때문에 전체적인 작업 처리가 3초를 지났기에 fallback 처리가 된다
- 해당 요청의 전체적인 작업 처리 자체가 3초이기에 retry조차도 실행되지 못한다.
- 더 나아가 TimeLimiter를 10초로 설정했다고 하더라도 retry까지 모두 계산하면 시간을 넘기때문에 retry를 진행하다 멈춰버린다
timeout의 값은 신중히 설정되어야 한다 그래서 기본적으로 TimeLimiter의 timeout 값은 CircuitBreaker와 slowCallDurationThreshold와 OpenFeign의 connectionTimeout, readTimeout 보다 크게 설정되어야한다. 그래야 응답이 조금 오래 걸리는 상황에서도 정상적으로 처리가 가능하다. 그 외에 slowCall에 대하여 재시도를 고려까지 한다면 더욱 신중히 값을 정해주어야 한다.
'프로젝트 > 항해99 개인 프로젝트' 카테고리의 다른 글
| 🚢 MSA의 동시성 제어를 위한 Lock 사용(feat. Redis의 분산락) (1) | 2024.04.30 |
|---|---|
| 🚢 Feign Client 와 RestTemplate (0) | 2024.04.30 |
| 🚢 재고 관리를 위한 동시성 제어 (Monolithic Architecture) (2) | 2024.04.27 |
| 🚢 WishList가 장바구니? (Redis 의 Hash타입 사용) (0) | 2024.04.26 |
| 🚢 이메일 인증 코드, Session 에서 Redis로 (0) | 2024.04.26 |