
Collection 자료구조의 대해서 배워보자
우리는 배열을 정렬할때 대부분 Arrays.sort와 Collections.sort를 사용한다
두개의 차이점은 코드에서 부터 크게 차이가 난다.
public void arrayTest() {
int[] arr = {1,2,3,4,5};
Arrays.sort(arr);
public void CollectionTest() {
ArrayList<Integer> list = new ArrayList<Integer>();
Collections.sort(list);정확히 다룬건 아니지만 이런식으로 사용하는것을 볼 수 있다. 그럼 이제 중요한것은 왜 나누냐는 것이다.
그리고 눈으로 보이는 확연한 차이점 인스턴스화와 제네릭을 왜 사용하게되는건지도 한번 알아보고자 한다.
Collections.sort
자바의 대표적인 자료 구조의 집합체라고 할 수 있다. Collections는 java Collections FrameWork의 의미부터 시작한다고 봐도 무방하지 않다고 생각한다. 저 위의 단어를 합쳐서 해석하면
일정 타입의 데이터들이 모여 쉽게 가공 할 수 있도록 지원하는 자료구조들의 뼈대(기본 구조)
자 여기서 기본 구조라 함은 바로 떠오르는것이 바로 Interface이다 Interface자체가 뼈대만 존재하는것이다.
Collections는 크게 List(리스트),Queue(큐),Set(집합)으로 나누어져있다. 이것이 형태에 따른 자료구조 이다.
그렇다면 그것에 따라 "구현"이 된 것들도 알아보자
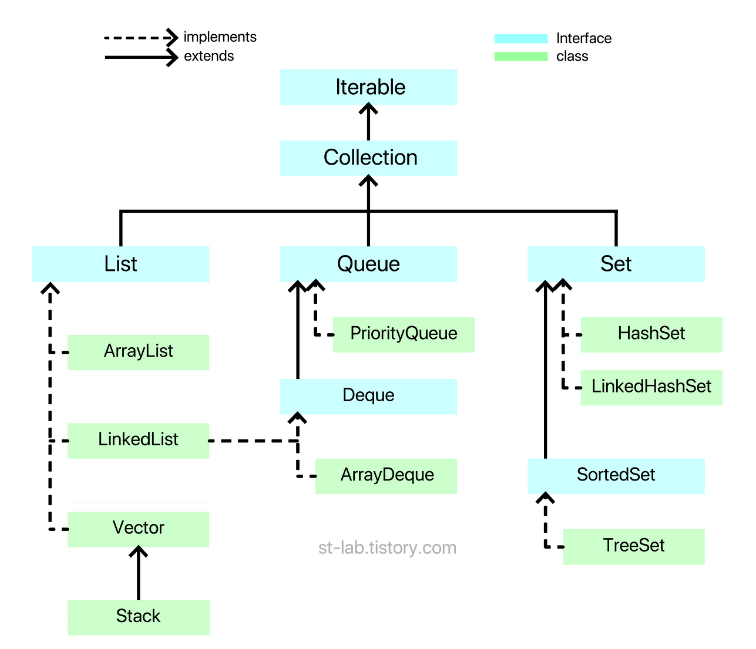
자 여길 보면 이해하는데 한결 쉽게 알아볼수 있을것이다.
점선은 구현관계이고, 실선은 확장 관계이다.
※Collection을 구현한 클래스 및 인터페이스들은 모두 java.util패키지에 있다.
자 하나하나 천천히 알아보자 List, Queue, Set 이 3가지는 형태에 따른 자료구조 라고 했다
여기서 Queue의 Deque와 set의 SortedSet은 조금 더 구체화 되어 형태에 따른 자료구조가 생성되어있다.
형태에 따른 자료구조들은 각각 "구현"되어 class로 제공된다.
녹색이 "구현된 자료구조"라고 생각하면 된다.
※ java는 Interface를 class파일로 쓰면 "구현한다"라고 표현한다.
여기에 있는 모든 class들은 모두 객체 형태로 내부 구현 또한 각각의 객체를 갖고 움직인다.
이 데이터들을 순회하며 "출력"하기 위해선 사용자들이 순회 방법을 안다거나 하나씩get() 같은 메소드를 통해 하나씩 꺼내와야한다.
List (리스트)
리스트는 대표적인 선형 자료구조이다. 순서가 있는데이터를 목록으로 이용할 수 있도록 만들어졌다.
1. ArrayList
ArrayList는 Object[] 배열을 사용하면서 내부 구현을 통해 동적으로 관리를 한다.우리가 흔히 사용하는 primitive배열과유사한 형태라고 생각하면 된다.
◐ 장점
= 최상위 타입인 object를 받기때문에 요소접근에서는 탁월한 성능을 보인다.
◑ 단점
= 중간에 요소의 삽입,삭제가 일어나면 하나하나 재배열을 해야하기 때문에 비효율적이다
2.LinkedList
데이터와 주소로 이루어진 클래스를 만들어 서로 연결하는 방식이다. 이를 노드라고 하는데 노드가 노드끼리 그물망처럼 연결되어있는것이다.
◐ 장점
= 삭제, 삽입의 경우 해당 노드의 링크를 끊거나 연결만 해주면 되기 때문에 매우좋은 효율을 낸다
◑ 단점
= 요소를 검색 할때 처음 노드부터 찾아야하는 노드가 나올때까지 모든것을 봐야해서 성능이 떨어진다
3.Stack
우리가 흔히들 알고있는 Stack이다. Stack은 LIFO(Last In First Out)방식을 사용하여 데이터를 쌓아올린다.
우리가 무언가를 쌓아올린 후 그것을 다시 내릴땐 가장 마지막에 내린다고 생각하면 굉장히 이해가 쉬울것이다.
※ Stack은 vector의 클래스를 상속받고 있다.
4. vector
쉽게 생각해서 ArrayList와 거의 같다. 똑같이 최상위 타입인 object 배열을 사용한다. 얘는 Collection이 있기 전부터 있었다. 그리고 항상 동기화를 지원한다. 많은 양의 정보를 순차적으로 접근하여 안전하지만 데이터가 작은곳에서는 ArrayList에 비해 성능이 떨어진다.
Queue (큐), Deque (덱)
1.Queue(큐)
큐는 stack과 다르게 FIFO(First In First Out)인 인터페이스 이다. 딱 해석처럼 읽으면 된다 먼저 들어가면 먼저 나온다.
가장 앞에 위치한 것을 head라고 부르고 마지막을 tail이라고 부른다.
2. Deque(덱)
Queue를 상속하고 있는 Interface이다. 같은 부류 이긴 한데. Queue는 단방향인것에 비해 Deque는 양쪽에서 삽입,삭제가 가능하다. Queue의 확장형이라고 볼수 있다. 카드덱과 비교를 한다
재밌는 사실 하나가 그림에 보면 LinkedList가 Queue쪽과 연결되어 있는걸 볼 수있다.
즉, LinkedList는 List를 구현하기도 하지만 Deque도 구현하고 Deque는 Queue를 상속받고 있으니 자연스레 연결된다.
그럼
LinkedList는 왜이렇게 다중 인터페이스를 포함하고 있을까
위의 List의 인터페이스들의 관점이 노드로 객체를 연결하여 관리하냐 Object로 배열을 관리하냐 의 차이였던것 처럼
Queue와 Deque를 LinkedList처럼 노드객체로 연결해서 관리하길 원한다면 사용하는것이다.
LinkedList와 ArrayDeque둘다 Deque를 구현하고 있고, Deque는 Queue를 상속한다.
결국 일반 큐를 선언할때는 LinkedList를 사용하면 되는것이다.
Queue<T> queue = new LinkedList<>();
Deque<T> queue = new LinkedList<>();로 둘의 차이점은 누굴 사용하냐의 차이만 있을것이다.
우선순위큐(PriorityQueue)는"데이터 우선순위"에 기반한다.인터페이스 자체가 오름차순을 기준으로 가면서 가장 먼저 있는 낮은 숫자가 높은 우선순위를 가지게 된다. 즉, 최댓값과 최솟값을 가져올때는 매우 유용하게 사용한다.
단! 사용자가 정의한 객체를 타입으로 사용한다면 Comparator 혹은 Comparable을 이용해 정렬방식을 직접 구현해주어야한다.
Set(집합/ 세트), SortSet
set은 재밌는 특징이 있다.
- 데이터를 중복해서 저장 할 수 없다
- 입력 순서대로의 저장 순서는 보장하지 않는다.
이 특징을 기억하며 또 천천히 한개씩 알아보자
1. HashSet
굉장히 많이 들어봤을것 같다.가장 기본적인 Set컬렉션의 클래스인데 , 입력순서를 보장하지도 순서를 보장하지 않는다.
hash에 의해 데이터의 위치를 특정시켜 해당 데이터를 빠르게 색인 할 수 있는것이다.
아이디 중복설정과 같다.
2. TreeSet
set의 특징을 그대로 가지고 있다. 특별한 점을 꼽자면 구현한 TreeSet은 데이터의 "가중치에 따른 순서"대로 정렬한다
중복되지 않으면서 특정 규칙에 의해 정렬된 형태의 집합을 쓰고 싶을때사용한다.
그렇다면 특정 구간의 집합 요소들을 탐색 할 때 매우 유용하다는 뜻이 될수있다.
3.LinkedHashSet
이름이 굉장히 길다. 이름에서 보듯이 모두 결합된 상태이다. 잘 보면 이름에 Link가 있다 이는 LinkedList로 보이며 Set의 특징 또한 바뀐다. LinkedList는 add를 통해 요소들을 순서대로 넣는다 즉, 첫번째부터 차례대로 출력하면 입력했던 순서대로 출력한다는 뜻이다.
이것의 가장 큰 장점은 중복은 허용하지 않지만 순서를 보장받고 싶을때 사용하면 된다.어떻게 쓰느냐에 다라 다르겠지만 굉장히 유용할수도 있다.
이런식으로 Collections.sort로 정렬을 하게 되고 우리가 인터페이스의 이름과 제네릭을 가져오는 큰 이유가 될수있다.